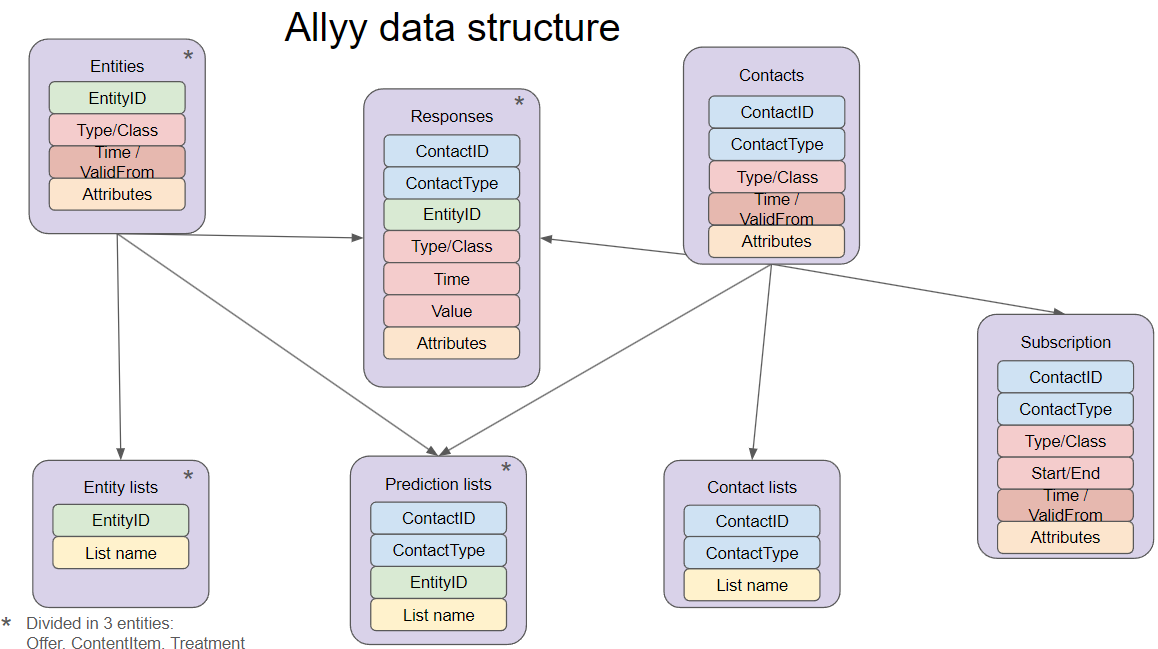
Data Mapping: Entities Description
Once you have a preview of the data, you need to map it to the allyy data structure, which organizes contact and interaction data.Revised Terminology for Clarity:
- Contacts: Individuals or entities that will interact with your system.
- Offers/ContentItem/Treatment: Objects or items that a contact can interact with. Examples include Offers (e.g., promotions), ContentItems (e.g., articles), and Treatments (e.g., telemarketing).
- Responses: Captures interactions between a contact and an object. This could include positive actions (e.g., clicks, donations) or negative actions (e.g., unsubscribes).
- Subscriptions: Represents agreements between a contact and an object (e.g., subscriptions to services). They can have start and end dates, or be ongoing if the end date is undefined.
- Lists: Collections of contacts or objects used in models or workflows (e.g., a list of target customers for a prediction).
Data Mapping Fields
When mapping your data to the allyy data structure, there are different categories of fields:- IDs: Unique identifiers for contacts, offers, or responses (e.g., ContactID, OfferID).
- Attributes: Characteristics of the data (e.g., age, gender, postal code).
- Classes and Types: Fields that help categorize data (e.g., Offer Type, Content Category).
- Valid From: Indicates when the data is valid from, useful for tracking changes over time.
- Mandatory Fields: Required fields that must be mapped (e.g., Subscription Start Date).
- Optional Fields: Enrich the entity with additional information but are not required (e.g., Subscription Frequency).